Wenn du eine umfangreiche Webseite betreibst, nutzt du sehr wahrscheinlich die Google Search Console (GSC). Oft tauchen dort Fragen zum Crawl Budget oder Meldungen wie „Gecrawlt – zurzeit nicht indexiert“ oder „robots.txt nicht erreichbar“ auf. In diesem Artikel erklären wir dir, wie diese Dinge zusammenhängen, wo wir als Hoster eingreifen können und wo die Grenzen unserer Möglichkeiten liegen.
Was ist das Crawl Budget und wie verhält sich der Googlebot?
Google steuert über eigene, sehr komplexe Algorithmen, wie oft und wie intensiv der Googlebot deine Webseite besucht. Das sogenannte Crawl Budget legt fest, wie viele Seiten deiner Website in einem bestimmten Zeitraum gecrawlt werden.
Aktuell beobachten wir, dass Google generell sehr „sparsam“ mit dem Crawl Budget umgeht. Besonders bei umfangreicheren Webseiten (ab ca. 1000 Unterseiten) kann es dauern, bis alle URLs von Google verarbeitet sind.
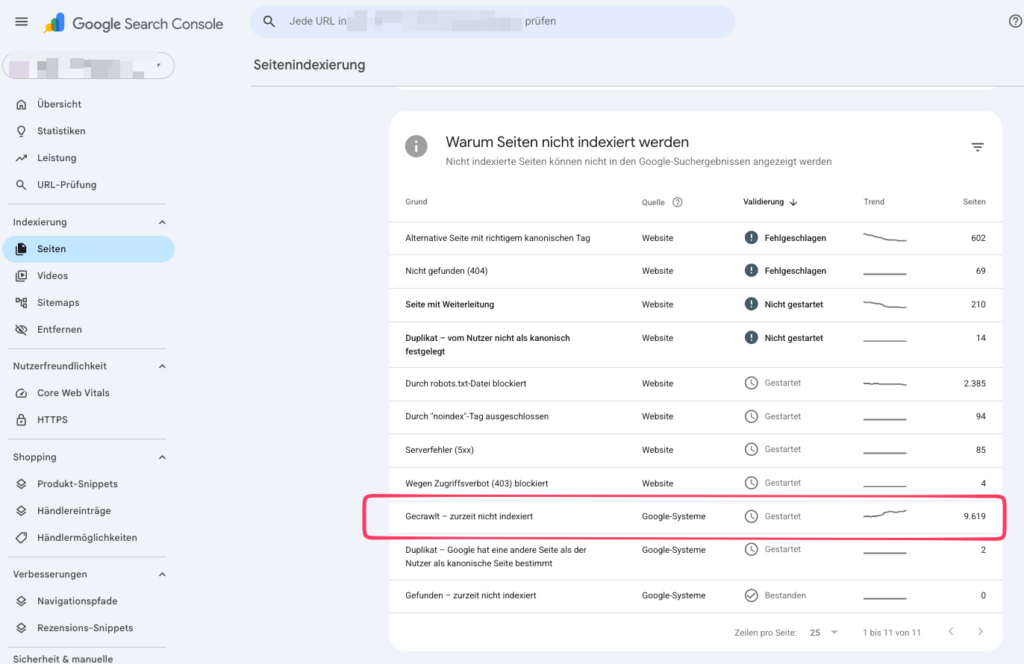
Die Meldung in der GSC: „Gecrawlt – zurzeit nicht indexiert“
…oder auch „Gefunden – zurzeit nicht indexiert“
In der Search Console tauchen oft zwei sehr ähnlich klingende Statusmeldungen auf. Der Unterschied zwischen beiden Meldungen liegt in der Phase, in der sich die URL befindet. Es ist im Grunde die Unterscheidung zwischen „warten auf Bearbeitung“ und „bewertet, aber abgelehnt“.
Gefunden – zurzeit nicht indexiert:
Google kennt die URL und hat sie vorgemerkt. Der Besuch durch den Googlebot (das Crawling) steht jedoch noch aus. Oft geschieht dies, weil Google seine eigenen Ressourcen schonen oder Serverüberlastungen vermeiden will.
Gecrawlt – zurzeit nicht indexiert:
Hier war der Googlebot bereits auf der Seite, hat den Inhalt gelesen und analysiert. Danach wurde jedoch entschieden, die Seite nicht in den Index aufzunehmen. Die Ursachen hierfür liegen meistens im Bereich Onpage-SEO. Häufige Gründe dafür sind mangelnde Relevanz, zu wenig oder zu „dünner“ Inhalt (Thin Content), fehlende interne Verlinkung oder doppelter Inhalt (Duplicate Content).
Diese Meldung bedeutet, dass Google deine Seite zwar gefunden und technisch abgerufen hat, sich aber noch nicht entschieden hat, sie in den Index aufzunehmen.
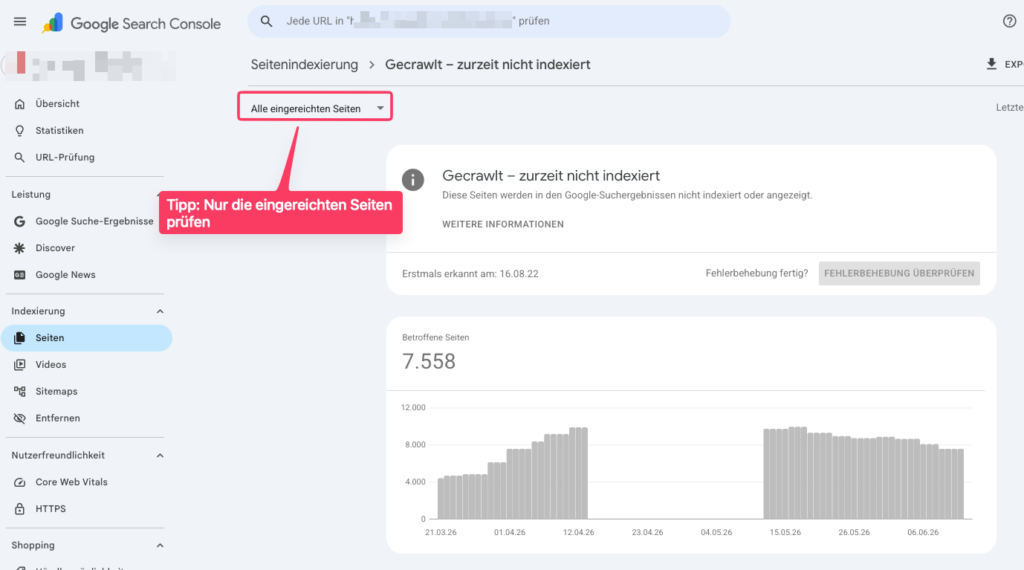
Wenn sich an diesen Statistiken tagelang nichts ändert, ist das kein Grund zur Sorge:
- Google pflegt die Daten in der Search Console nicht in Echtzeit.
- Die Statistiken werden immer zeitversetzt mit einigen Tagen Verzögerung aktualisiert.
- Ein scheinbarer Stillstand in den Diagrammen der GSC ist daher oft ganz normal.
Nutze auf jeden Fall das offizielle Google URL-Prüftool, um zu sehen wie der Googlebot deine Webseite sieht. Damit kannst du insbesondere testen, ob deine robots.txt und sitemap_index.xml (manchmal auch sitemap.xml) einwandfrei für den Googlebot abrufbar sind. Auch einzelne Seiten kannst du damit stichprobenartig testen (z.B. die Startseite).
Was ist unsere Verantwortung als Hoster?
Als dein Hostinganbieter sorgen wir dafür, dass die technischen Rahmenbedingungen deines Servers für den Googlebot optimal sind. Unsere Aufgaben umfassen:
- Erreichbarkeit gewährleisten: Wir stellen sicher, dass wichtige Dateien wie die
robots.txt(Kostenloses Prüftool, ob deine robots.txt erreichbar sind) und deine Sitemaps (z. B.sitemap_index.xml) serverseitig einwandfrei und fehlerfrei abrufbar sind. (Kostenloses Prüftool, ob deine sitemap_index.xml erreichbar ist). - Sicherheit und Bot-Traffic verwalten: Auf unseren Servern läuft professionelle Sicherheitssoftware (z. B. Imunify360 WAF), die deine Seite vor schädlichen Bots schützt.
- Fehlerbehebung bei „False-Positives“ (sehr selten): Bei extrem hohem allgemeinen Bot-Traffic kann es in seltenen Fällen vorkommen, dass das Sicherheitssystem eine legitime Googlebot-IP fälschlicherweise blockiert (ein sogenanntes False-Positive). Wenn die GSC meldet, dass die
robots.txtnicht erreichbar ist, prüfen wir die Server-Logs. Betroffene, offizielle Google-IPs setzen wir in einem solchen Fall permanent und serverweit auf eine Whitelist. Damit sind serverseitig alle Ampeln auf Grün gestellt und der Googlebot wird nicht mehr blockiert.
Wo wir als Hoster keinen Einfluss haben
Um falsche Erwartungen zu vermeiden, möchten wir hier ganz transparent sein. Folgende Punkte liegen vollständig in der Hand von Google:
- Crawl-Häufigkeit: Wir haben leider keinen direkten Einfluss darauf, wie oft der Googlebot deine Webseite besucht.
- Crawl Budget erhöhen: Wir können das von Google gewährte Crawl Budget nicht verändern oder erhöhen. Dies ist ein Thema, das wir als Hoster nicht beeinflussen können.
- Echtzeit-Daten in der GSC: Wir können nicht beschleunigen, wie schnell Google die Diagramme in deiner Search Console aktualisiert.
Was du selbst tun kannst
Um dein dir zur Verfügung stehendes Crawl Budget bestmöglich zu nutzen, hast du als Webseitenbetreiber folgende Möglichkeiten:
- robots.txt optimieren: Du kannst deine
robots.txtum Regeln ergänzen, damit doppelte oder irrelevante Inhalte gar nicht erst vom Googlebot gecrawlt werden. So lenkst du das begrenzte Budget gezielt auf deine wichtigsten Unterseiten. - Sitemap neu einreichen: Du kannst in der GSC deine Sitemap neu einlesen lassen, um Google einen frischen Anstoß zu geben. Prüfe aber bitte, dass du keine Sitemaps doppelt eingereicht hast.
- Manuelles Crawling anstoßen: Einzelne, besonders wichtige URLs kannst du in der Search Console manuell zum Crawling beantragen.
Fazit: Wenn serverseitig alles fehlerfrei läuft, die Sitemap indexiert ist und die robots.txt abgerufen werden kann, steht einem erfolgreichen Crawling technisch nichts mehr im Wege. In diesem Fall hilft meist nur etwas Geduld, bis Google die Seiten verarbeitet und die GSC-Daten aktualisiert hat.